


Amazon S3 (Simple Storage Service) is a highly scalable and durable object storage service provided by AWS. It is designed to store and retrieve any amount of data from anywhere on the web. S3 is widely used for a variety of purposes, including data backup and restore, content distribution, data archiving, and hosting static websites.
Here are some key features of Amazon S3:
Object Storage: S3 provides object storage, which means that data is stored as objects in buckets. An object consists of the actual data, a unique key, and metadata associated with the object. Objects can be up to 5 terabytes in size.
Scalability: S3 is built to be highly scalable. It can store virtually unlimited amounts of data, and you can seamlessly increase or decrease your storage capacity as needed. S3 automatically scales to accommodate your storage needs without any upfront planning.
Durability and Availability: S3 is designed for durability and high availability. It stores multiple copies of your data across multiple facilities within a region, ensuring that your data is highly available and protected against hardware failures.
Security: S3 offers robust security features to protect your data. You can control access to your buckets and objects using AWS Identity and Access Management (IAM) policies, bucket policies, and Access Control Lists (ACLs). S3 also supports encryption for data at rest and in transit, including server-side encryption and client-side encryption.
Data Management: S3 provides a range of features to manage your data effectively. You can organize objects into buckets and use prefixes and delimiters for logical grouping. S3 supports versioning, which allows you to keep multiple versions of an object. Lifecycle policies enable you to automatically transition objects to different storage classes or delete them after a specified time.
Access Control and Permissions: With S3, you can grant fine-grained access control to your objects. You can define access policies at the bucket level or at the individual object level. S3 also integrates with AWS Identity and Access Management (IAM) for centralized access management and fine-grained permissions.

Amazon S3 is a highly reliable, scalable, and cost-effective storage solution. It is widely used by organizations of all sizes to store and manage their data in the cloud. Whether you need to store backups, host static websites, or build data-intensive applications, S3 provides a flexible and reliable storage platform to meet your needs.
Task-1
Launch an EC2 instance using the AWS Management Console and connect to it using Secure Shell (SSH).
Log in to the AWS Management Console and click launch instance

Launch an EC2 instance by providing all the default configurations as we have seen in my previous blogs.
Connect to the server using SSH. Open Command Prompt in your local system and navigate to the private key “.pem” file location.

Paste and copy ssh command in your Terminal.
Create an S3 bucket and upload a file to it using the AWS Management Console.
- Navigate to the S3 page in the AWS console.

Click on the "Create bucket" button.
Enter a unique name for your bucket, select the region you want to create it in, and then click "Create."




Click on create bucket ,Once your bucket is created, click on its name to open it.

- Now click on Upload or Add files to upload a file to the S3 bucket.

The file is now uploaded to the S3 bucket.

Access the file from the EC2 instance using the AWS Command Line Interface (AWS CLI).
Navigate to your instance and install AWS CLI.
Install the AWS CLI by following the instructions for your operating system: https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2.html
Check AWS CLI version.

Once you have installed the AWS CLI, open a terminal and run the command “aws configure” to configure your account credentials.
Enter your AWS Access Key ID and Secret Access Key

- List s3 buckets using below command:

You can use the aws s3 cp command to copy the file from your S3 bucket to your EC2 instance and view content of file using cat command.
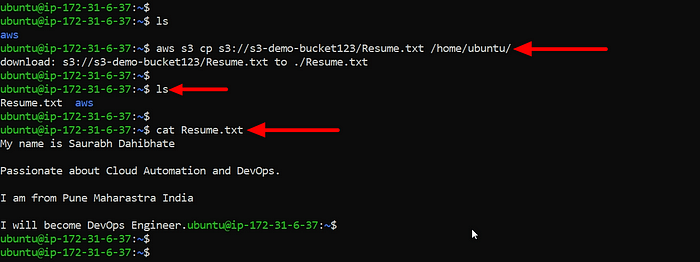
Task-2:
Create a snapshot of the EC2 instance and use it to launch a new EC2 instance.
Navigate to AWS EC2 service. Click on “Snapshots”

Click on the “Create snapshot” button.

Select the EC2 instance that you want to create a snapshot.

Snapshot created.

Use snapshot to launch a new EC2 instance.
click on Actions and select “Create image from snapshot”

In the “Create Image from snapshot” window, enter a name and description for the image.

Click on “Create Image”.

- Once the image is created, go to the “AMIs” section in the EC2 Dashboard.
Now, Check image is created.

Select the newly created AMI, right-click on it, and select “Launch Instance.”

In the “Launch Instance” window, choose the configuration options for the new instance.
Choose the VPC and subnet you want to launch the new instance in.
In the “Add Storage” section, you can choose to modify the storage volumes as per your requirements.
Review the instance details and click “Launch instance” to launch the new instance.

Connect to instance using SSH:

- Here login as the user “ubuntu” rather than the user “root”
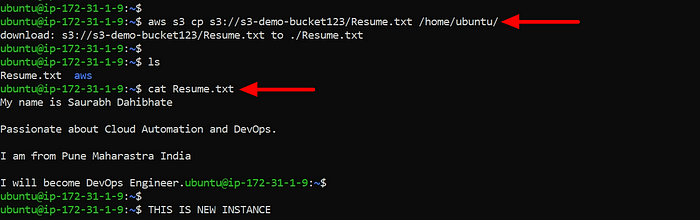
Download a file from the S3 bucket using the AWS CLI.
“aws s3 cp”command to download the file from your S3 bucket to your EC2 instance.
aws s3 cp s3://BUCKET_NAME/PATH/TO/FILE /PATH/TO/LOCAL/FILE
Verify that the contents of the file are the same on both EC2 instances.
AWS CLI commands for S3:
Here are some commonly used AWS CLI commands for Amazon S3:
aws s3 ls — This command lists all of the S3 buckets in your AWS account.
aws s3 mb s3://bucket-name — This command creates a new S3 bucket with the specified name.
aws s3 rb s3://bucket-name — This command deletes the specified S3 bucket.
aws s3 cp file.txt s3://bucket-name — This command uploads a file to an S3 bucket.
aws s3 cp s3://bucket-name/file.txt — This command downloads a file from an S3 bucket to your local file system.
aws s3 sync local-folder s3://bucket-name — This command syncs the contents of a local folder with an S3 bucket.
aws s3 ls s3://bucket-name — This command lists the objects in an S3 bucket.
aws s3 rm s3://bucket-name/file.txt — This command deletes an object from an S3 bucket.
aws s3 presign s3://bucket-name/file.txt — This command generates a pre-signed URL for an S3 object, which can be used to grant temporary access to the object.
aws s3api list-buckets — This command retrieves a list of all S3 buckets in your AWS account, using the S3 API.
Thank you for giving your precious time to read this blog/article .
Happy Learning😊😊!!!!